
转载自:https://zhuanlan.zhihu.com/p/296329343
黑帕云版权所有,未经允许,禁止转载
太长不读版
- 什么是黑帕云技术博客
- 黑帕云真实的前端性能案例
- 调优工具 FPS extension 和 Chrome Performance 教程
- 性能优化的一些思考
各位好,这里是 黑帕云技术博客 ,我是黑帕云的软件开发工程师毛超。在这里,我们会把不定期的分享开发黑帕云过程中值得总结的知识,经验,最佳实践,甚至是教训。希望通过技术博客,让更多的工程师认识我们,认识黑帕云。
惯例来一个广告吧,黑帕云 —— 新一代的数据协作平台, 让任何人都能通过最熟悉的技能,构建满足其需求的工具,使软件创建民主化。你值得拥有:)作为程序员,也可以用黑帕云方便快捷的搭建自己的数据管理中心,不一定什么东西都要自己动手写代码,模板中心有不少好用的应用,值得一看。
引子
在Reactjs大行其道的今天,前端性能优化似乎与开发者越来越远,因为 React 确实很快。React凭借着 Virtual DOM 的抽象,让开发中只关注组件中的 state 和 props,框架自己操作浏览器更新 DOM,达到最佳性能。回想起当年初识 React,曾被这个“大胆的想法”惊的“直呼内行”,不过现在想想,有那么点类似于经典的“指针段子”: C++说,指针太重要了,一定要让程序员自己管理。Java说,指针太重要了,一定一定不能让程序员自己管理(听懂鼓掌)。
但 React 也不是万能的,在某些场景下,React 也会很慢,慢的令人发指。问题不外乎两种:要么就是开发人员自己犯了错误,要么就是你的业务场景已经超出了 React 能处理的范围。可惜在绝大多数情况下,都是开发自己的问题。下面通过一个真实的案例,分享一下黑帕云前端性能调优的故事。
性能问题出现
性能 bug 比功能 bug 更难以察觉
首先简单的介绍一下黑帕云中的基本概念:
- 应用 :帮助客户完成某种功能的应用,比如“ 工资表管理 ”,一个 应用 包括多张 数据表
- 数据表 :管理应用某一类数据的集合,比如 工资表 , 员工 等,记录了每一个员工的工资信息
某天,黑帕云的 CEO 米高给我反馈,说他在应用中切换数据表时不够流畅,没有那种“丝般顺滑”的感觉,并且在数据较多的时滞后感更加明显,让我想想办法解决。
当时的第一反应是有点懵逼的,CEO 感觉不够“顺滑”,可是我感觉挺好的呀,这玩意见仁见智怎么搞(╯‵□′)╯︵┻━┻
冷静分析之后,想起来页面的 帧率 就可以度量页面的顺滑度。说起帧率有的同学可能有点陌生,但说起 FPS 你肯定听过。 FPS (frame per second) 每秒帧数,简单来说就是每秒显示多少个画面。FPS 的值越高,页面越流畅。在这里我推荐 FPS extension,一个chrome的插件,可以非常方便的显示页面实时帧率。
FPS Extension,需要富强chrome.google.com
测试之后发现在表格切换的时候,帧率会急速下降到个位数,难怪米高会觉得不够流畅(最优帧率是60,越高越好)。这种卡顿大概率是在更新 DOM 时发生了什么,阻塞 UI 渲染线程导致的,我得去看看代码了。

图1.出现了“帧率深渊”,并伴随严重的卡顿,体验不够好
Review 代码
不被别人骂 WTF 的代码就是好代码
过了一遍代码,加载数据表页面逻辑大致如下:
- TablePage 组件发送 API 请求获取该数据表的所有 Records(一个 record 代表一行数据)
- 获取成功后,dispatch redux action 将所有 records 写入 redux store(就是 redux 经典的那一套)
- TablePage 组件监听 state.records 的变化,开始进行渲染
从代码中没有发现什么有价值的线索,初步说明开发没有犯低级错误导致性能问题。那么根据上述代码逻辑,有可能是下面动作慢了:
- api 处理请求慢了
- Reducer 函数慢了
- TablePage 组件渲染新页面慢了
通过 chrome 的 network 看到请求并不慢(给后端同学甩锅时要有理有据),那么首先怀疑 Reducer 函数吧。
Reducer 慢?
一项工作如果你无法度量他,你就无法优化他
根据 React 的定义,Redux Action 是一个简单的 js 对象,用来触发 Reducer 函数更改 Redux Store 里面的数据。在用户切换数据表时 dispatch 了不止一个 action ,需要找出最慢的那一个。NPM包 redux-perf-middleware 是 一个redux 的 ,可以在浏览器的console中输出处理每一个action 的时间。
使用起来也非常简单,加载redux的middleware里面就可以了
//记得只在dev环境下使用
import reduxPerfLogger from 'redux-perf-middleware';
const middleware = process.env.NODE_ENV !== "production"
? [reduxPerfLogger ,getDefaultMiddleware()[1]]
: getDefaultMiddleware();
安装完成之后刷新页面,在浏览器里测试了一下来回切换5000条Records的数据表,就可以看到输出结果。
可以看到处理 getTableInitialRecordsSuccess action 花了快 400ms,难怪帧率只有个位数。Review 代码时没觉得 Reducer 里面有什么特殊的逻辑,不应该这么慢,看来我们需要进一步找出 Reducer 的性能热点。
Reducer 慢!
如果要把页面帧率优化到最优的 60 帧,那就意味着页面一次刷新时间不能超过 1000ms / 60 = 16.67 ms。
要想知道某一段逻辑哪里慢,当然可以通过 console.log 打印处理时间,不过我更加推荐使用 chrome devtool 中的 performance 工具,可以非常方便找出页面某一段时间内的页面的性能相关数据。
使用方法也很简单,打开你想要测试的网页,打开 chrome 的 devtool ,选中 performance,然后点击下面的录制按钮,接着在页面开始操作,操作完成后点击结束按钮,就能看到分析结果了。切记要用打包压缩过后的js跑,并且保证浏览器没有开启任何多余的插件,保证环境的干净对测试很重要!
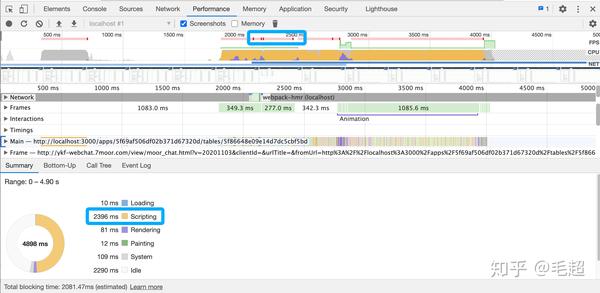
图4. chrome performance的输出结果
从图4中可以看到,最上面的一块区域是 总体概览的时间轴 ,记录了测试过程中的起点和终点(蓝色方框中突出的 红色小点 就是浏览器发现的卡顿现象)。中间一块区域包括了网络调用情况,主线程,页面交互等数据。最下面一块区域是各种总结图表,可以看到在我切换数据表的 4898ms 里,JS 一共花费了 2396ms 。(大家有兴趣的话我再单开一篇好好讲讲 performance 工具)
我们可以通过改变 时间轴的起点和终点 选中感兴趣的一段时间内浏览器的性能数据,比如我选中了“数据表内容变化”的一段时间,重点查看 JS 运行情况,
最下面的表格显示了JS的运行情况:
第一列是 Self Time ,指的是完成函数当前的调用所需的时间,仅包含函数本身的声明,不包含函数调用的任何函数。
第二列是 Total Time ,指的是完成此函数和其调用的任何函数当前的调用所需的时间。
举个例子,下面的 foo 函数, Total Time 是 35ms, Self Time 是 15ms。
const foo = ()=> {
//foo自己的逻辑,花了10ms
bar(); // 调用bar函数,花了20ms
//foo自己的逻辑,花了5ms
}
按照 Self Time 排序,会更容易找到性能热点。通过表格的第一项就找到了 records.ts 文件(啪的一下,就找到了,很快呀),就是 Records Reducer 的处理文件,从调用链看,问题出现在调用 lodash includes 方法上,一共花了 462ms
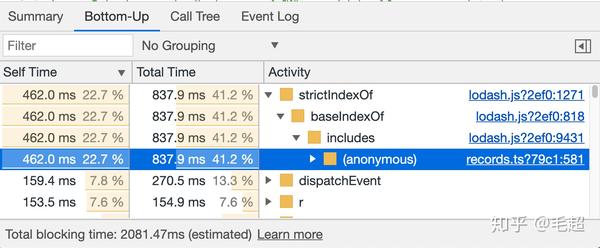
图6. 定位到 records.ts 文件的性能问题,通常方法的调用栈比较深,需要有点耐心找找有没有应用自己的方法或者文件。
好,那我们打开代码,看看调用 includes 方法的上下文。通过分析发现是这么做的
- 从 redux action 中获取 records 数组,循环 records 数组
- 调用 updateRecord 方法,将 record 放入 store
- 在 updateRecord 方法中,用 includes 判断 record 是否已经存在于 redux store 中的 recordIdList 中
- 如果 record 已经存在,则不修改 recordIdList,如果 record 不存在,将新 record 放入recordIdList 中
仔细分析一下就会发现,这种做法在大数据量下确实有问题。 假设 store 中已经存在 m 条 records,那么在处理新返回的 n 个 records时,updateRecord 方法就会在 m 个元素的数组上执行 n 次 includes 。假设 m 和 n 都是5000的话,计算量还是 很恐怖的。
破解问题
接,化,发
如何破解呢?结合业务场景思考一下,当我们切换表时后端总会返回该表全量的数据,所以是不需要用 includes 判断“是否存在过”,我们可以直接通过全量数据生成一个新的数组,然后覆盖原来的老数组,就避免了重复调用 includes。

图8. 新方案的示例代码
和代码的原作者沟通了一下,发现最初 updateRecord 是为了更新某一个 record 设计的,用在“更新全表 records ”只是为了代码复用而已,新方案明显更优。
优化之后效果还是很不错的,没有了“帧率深渊”,chrome performance 中也没有明显的慢方法

图9. 优化后的FPS
也许有同学会问为什么切换数据表时 api 后端永远返回全量数据而不是增量数据?这是一个好问题,简单一点回答,其实黑帕云已经支持了,当数据量超过某个阈值后,就会开启增量加载模式,保证超大数据量下的使用体验。
结尾
万事开头难,然后中间难,最后结尾难
修改上线之后,CEO反馈“切换数据表顺滑多了”,总算是有所改善:)
回顾一下上面的工作,思考之后值得分享的是:
- 在解决性能问题时,定位问题永远是最困难的,所以要认真琢磨如何度量现状,如何精准的定位问题,这很重要
- 写代码时,要贴合业务场景,不要一味的追求代码复用
- 为了性能要求,可以重写某段逻辑,甚至使用一些“黑魔法”,只要加上注释就好
- 本地开发时,依然要尽可能贴近真实环境,包括数据量,数据内容的真实性等,这样会尽早暴露问题
好,这一篇就写到这里,算是一个开胃菜。下一篇我会继续分享更多干货,包括 react profiling 工具的使用, redux store 设计 , 减少React组件重复刷新 等最佳实践,敬请期待。
最后的最后,我们正在招聘
工作地点: 成都/西安
- #黑帕云的最新职位来了#
- 前端技术:React + Redux
- 后端技术:Java + Python
- UI 设计师,UX 设计师
- 移动 Web 及客户端:React Native + ReactXP
我们提供什么?
- 轻松愉快的互联网工作氛围,如无话不谈、亦师亦友的工作伙伴;
- 丰富多彩的员工活动,如 Gym Time 、分享会、郊游、户外拓展、跨城市团建、企业周年庆等;
- 业务之外的其他成长投入,如专业技巧培训、职业素养培训、管理能力培训等;
- 顶配MacBook Pro + 4K 显示器,购买工作必要的正版软件;
- 作为早期创始员工,你有机会获得期权,共同分享创业的成长;
- 其他福利:全额五险一金、年终奖、节日补贴、双休、法定假期 /带薪年假、团建活动、员工旅游、不定期福利大放送。
感兴趣的小伙伴们可以通过以下方式投递简历;
将简历发送至: job@hipacloud.com
在线简历投递:https://lyv12j.hpapps.cn/forms/ln2je3
感谢大家的阅读。